Machine Learning Simplified - Part I
- Sachin Tah
- Nov 23, 2020
- 7 min read
Updated: Nov 27, 2020

Human Intelligence is quoted as a "Mental quality that consists of the abilities to learn from experience, adapt to new situations, understand and handle abstract concepts, and use knowledge to manipulate one's environment." In a nutshell, it is the ability of humans to learn from their experience and make appropriate decisions if a similar situation arises.
Humans use neurons to store information in memory. As per an article published in https://www.scientificamerican.com/, human brains are capable of holding approximately 2.5 petabytes (or a million gigabytes) of data, which is more than sufficient to hold information of a lifetime. As our experience (data) grows, our decision-making capability (intelligence) becomes better as we learn from our past mistakes. Better to put it like this "We should learn from our past mistakes 😄".
I don't want to confuse you, the point which I want to explain is that decision-making is proportional to the amount of information/data supplied.
Artificial Intelligence

Artificial Intelligence is a field of computer science where machines are developed to act intelligently mimicking humans or animal intelligence. AI as a whole is still a broad term and an area of development and research. AI is divided into 5 major categories which include Machine Learning (ML), Natural Language Processing (NLP), Expert Systems, Neural Networks, and Robotics. These categories are so broad and still evolving that you need a decade each to get expertise in each one of these. We will be focusing only on Machine Learning (ML) and its algorithm.
Machine Learning (ML)
In simple terms, ML gives computers the ability to learn from data and assist in making decisions for a new set of data.
As per Arthur Samuel who wrote checker playing program way back in 1950, "Machine Learning is a field of study that gives computers the ability to learn without being explicitly programmed".
A more formal definition was introduced by Tom Mitchell in 1998, as per him "A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.".
Confusing right? Let me try to explain this in simple terms, consider

Experience (E) - In simple terms, you can consider E as the amount of data supplied to any program. For example, if you have a program to recognize handwritten characters (Character Recognition), E will be the number of handwritten examples you have supplied to your program.
Task (T) - A task is a work which you assign to your Machine Learning (ML) program and expect output out of it. In the handwriting recognition example, a Task will be "Take handwriting input as an image and recognize correct letters"
Performance Measure (P) - Performance is the measure of instances where the program predicts correct output. In the handwriting example, P will be the measure of results where your program came up with the right answers.
So in very basic terms, P should improve with E. The more and more data you provide to your ML program, the better results you get out of it.
ML has already started playing a significant role in our day to day life, be it login on a mobile device or tagging a friend on Facebook. Let me provide you some examples where ML is already being used by us
Character Recognition - Widely used use case where contents of scanned documents are extracted and stored as text.
Face & Image Recognition - We use face recognition multiple times a day in order to login to our mobile devices. Image recognition is used in self-driving cars, google lens, visual search engines, Virtual reality & Augment reality.
Virtual Assistance - Alexa, Siri & Google are virtual assistance already available in the market. These assistants help us in performing various day to day tasks like making phone calls, getting directions, blocking calendar, and also connects to your home appliances in order to operate them via verbal commands.
Filtering Spam Emails - This ML algorithm is used by email providers like Gmail, Hotmail, Yahoo, etc. to filter spam emails from the rest and move them automatically to the junk folder
Online Fraud Detection - ML is used by payment gateways, aggregators, and processors to detect payment frauds based on behavioral patterns and various other factors
These are just some of the use cases of ML, however, as of today, ML is used in almost every business sector. More and more efforts are being made to disrupt the market.
Machine Learning Algorithms
When we are trying to solve a problem using Machine Learning, it is important to begin in the right direction which starts with the identification of the right algorithm we will be using in order to solve a problem.
Let us focus on the algorithms used in Machine Learning. Broadly there are three categories of ML algorithms,
Supervised
UnSupervised
Reinforcement
Supervised Learning
In the supervised learning algorithm, we supply a dataset (data) to the ML program which consists of a set of inputs and correct answers for each input. This algorithm predicts output based upon this information. This dataset is also called data with labeled output.
Confusing? Let me try to explain this with a simple example,

With supervised learning, you have input data (x) with the associated correct answer (y) for each input x. The algorithm learns from this input data and come up with a trained model. This trained model is not capable of predicting the output for a supplied input.
For example, suppose you want to predict the inflation rate for a future month based upon data from the past 10 years. (The term inflation means the devaluation of money caused by a permanent increase of the price level for products (consumer goods, investment goods)).
So now you have a dataset that consists x as date and y as the inflation rate. Now since you supply this dataset to your learning algorithm it knows for a given set of inputs what is the output.
X = { 20-01-2001, 20-02-2001, 20-03-2001, 20-04-2001, 20-05-2001, 20-06-2001}
Y = { 3.2, 4.6, 6.7, 5.3, 4.5, 4.3 }
So on a date, 20-01-2001 inflation rate was 3.2, for 20-02-2001 inflation was 4.6 and so on. (This is just a partial list for explanation purposes.)
For input x = 20-01-2001 correct answer is y = 3.2
For input x = 20-02-2001 correct answer is y = 4.6
This algorithm learns from this dataset and creates a model. This model helps in predicting the inflation rate for any future date supplied. Yes, there will be other factors as well as affecting inflation, which we will discuss in subsequent discussions.
The supervised learning algorithm is divided into two categories Regression & Classification depending upon the kind of output it produces.
Regression
A Supervised algorithm is termed as Regression if the output we are trying to predict is real and continuous.
Some examples of Regressions are,
Predicting the inflation rate depending upon date or month
Predicting the salary of an individual based upon the number of years of experience he possesses.
Classification
A Supervised algorithm is termed as Classification if the output we are trying to predict is discrete, which means that the output is a category ex. "Red" or "Green", "Yes" or No" or "True", "False".
Some examples of Classifications are,
Predicting if an email is "Spam" or "Not Spam"
Predicting if the input image is "Car" or "Truck"
Unsupervised Learning
Unsupervised learning has no supervision or guidance available with the input data. There is no label or output associate with the data. We need to find structure and patterns in the given data which is meaningful. This algorithm is also called a clustering algorithm.

Let me give you an example where we humans already use such an algorithm to use data points as references to find meaningful structure and patterns
Suppose we want to conduct an inter-school badminton competition for classes 8,9 and 10. A total of 500 students have enrolled in this competition. Now in order to conduct these matches, we have to come up with different categories so that everyone gets a fair chance during the competition.
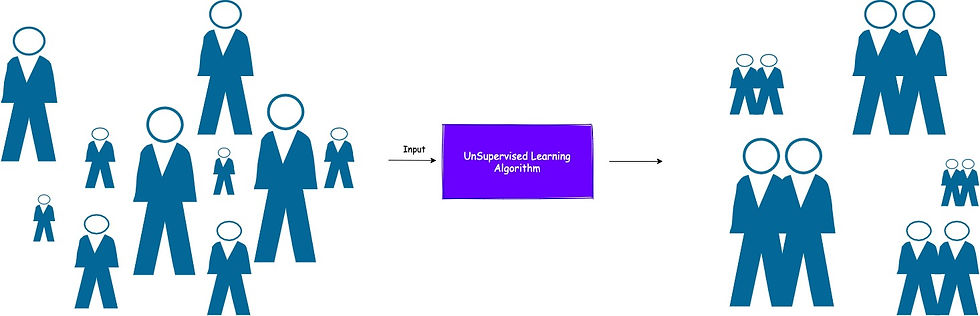
We will try to find some patterns in the student data, we have received student name, age, sex, class, weight, and height. Now instead of blindly going by student's class, we decided to create categories of students depending upon student sex and student height. In all, we created 10 different categories.
Now, any new student enrollment is first categorized depending upon sex and height and placed in any one of the 10 categories and then allowed to take part in the competition in that category only
Conceptually we are going to perform the same with an unsupervised learning algorithm.
We can use an unsupervised learning algorithm for
Grouping online shopping customers depending upon past orders in order to run a campaign depending upon customer groups
Online fraud detection depending upon user behavioral patterns
Recommendation systems, for example, OTT (Over-the-top) platforms like Netflix recommends the right content tailored for each user depending upon user viewing pattern
Following are two different types of an unsupervised algorithm
Clustering - Clustering as the name suggest is trying to find some kind of structure in the input data.
Association - Associate tries to find some kind of associations among the data. For example, a person who booked a flight ticket is more likely to book a cab.
Reinforcement Learning
Before I explain the Reinforcement learning algorithm, it is important to understand the following terms with respect to reinforcement learning
Agent - Agent is the ML algorithm that learns by performing various actions
Environment - Environment is the world with which the Agent interacts in order to solve a problem, the problem could be anything from finding the shortest distance from point A to B or applications in self-driving cars
Reward - Reward is some kind of positive feedback from the environment to the Agent to let him know that the step it has performed is correct
Observation - Observation is an internal state within the environment
Action - Actions are the steps performed by the Agent
Reinforcement learning uses observations(feedback) gathered by the interaction with the environment and aims at solving a given problem by taking optimal actions. In the process, the agent learns from its experiences of the environment until an idea behavior is reached.

In simple words, the algorithm tries to solve a problem in the environment by taking minimal actions and enhance itself from feedback. In the above example, the objective of the Agent would be to reach the Finish point using minimum distance.
In subsequent parts of this series will go through details of each of these algorithms for hands-on example.
Happy Reading...
Comments